Multi-agent systems are quickly becoming a practical way to turn a vague prompt into structured, reliable work products—especially for research-heavy tasks. Instead of asking one model to do everything, you split responsibilities across multiple specialized agents, give them clear output formats, and run an iterative quality loop. The result is usually more controllable, easier to debug, and better aligned with real-world workflows such as research, drafting, review, and final editing.
What this CAMEL multi-agent pipeline is designed to do
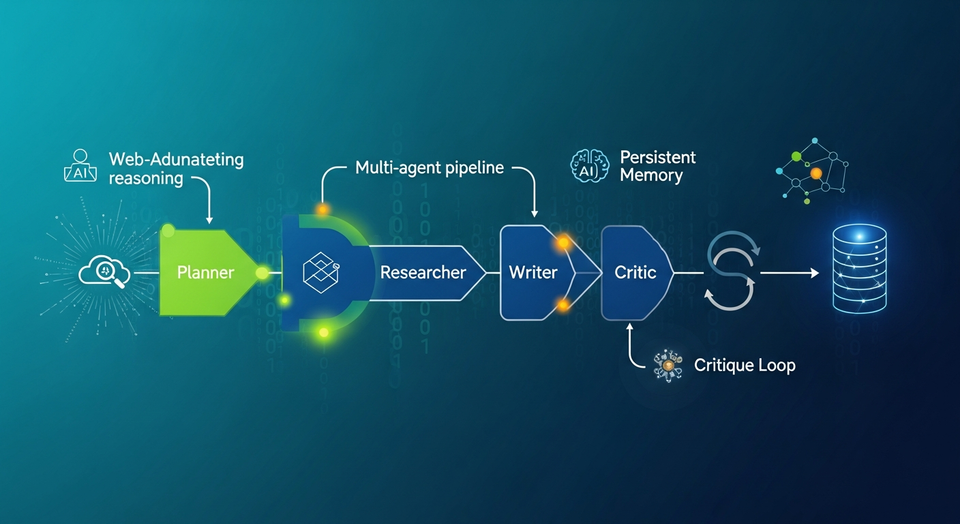
This article walks through an end-to-end multi-agent research workflow built with the CAMEL framework. The pipeline is structured as a small “society” of agents—Planner, Researcher, Writer, Critic, and Finalizer—that collectively transform a high-level topic into a polished, evidence-grounded research brief.
The core goals of the design are:
- Role clarity: each agent has a single responsibility and a defined contract for what it must output.
- Tool-augmented reasoning: the Researcher is enhanced with web search to ground findings in external evidence.
- Quality control via critique: drafts are reviewed by a Critic agent, and revisions are applied by a Finalizer.
- Continuity: a lightweight persistent memory layer stores artifacts from each run, enabling reuse across sessions.
The accompanying notebook with the full implementation is available via FULL CODES here.
Environment setup: dependencies and secure OpenAI API key handling
The workflow begins with standard environment preparation: installing dependencies and securely loading credentials. The implementation installs camel-ai[all], python-dotenv, and rich to support the agent framework, environment handling, and clearer console output.
For authentication, the OpenAI API key is loaded in a way that avoids accidental exposure. The code attempts to read OPENAI_API_KEY from Google Colab secrets via google.colab.userdata. If that fails, it prompts for the key using a hidden input (getpass). Either way, the key is set in os.environ["OPENAI_API_KEY"], so downstream components can use it without hard-coding secrets.
This matters operationally: pipelines that involve multiple agents, tools, and runs can end up logging more than you expect. Using Colab secrets or hidden prompts reduces the risk of leaking credentials in notebooks, screenshots, or shared repos.
Standardizing model behavior with ModelFactory
After environment setup, the pipeline creates a shared model instance using CAMEL’s ModelFactory. This provides a single configuration point that every agent can reuse, helping keep behavior consistent across the entire workflow.
In the reference implementation, the model is configured with:
- model platform:
ModelPlatformType.OPENAI - model type:
ModelType.GPT_4O - temperature:
0.2(to encourage more stable, reproducible outputs)
Using one shared model instance also simplifies debugging: if outputs drift or become inconsistent, you have a single place to adjust generation parameters.
Adding lightweight persistent memory with a JSON-backed store
A key feature of this tutorial pipeline is a simple persistence mechanism that stores outputs across runs. Instead of introducing a full vector database or external storage service, the workflow implements memory as a local JSON file: camel_memory.json.
The memory layer includes helper functions that:
- Load memory if the file exists, otherwise initialize an empty structure (with
{"runs": []}). - Save updated memory back to disk.
- Append a run with a timestamp (
ts), thetopic, and the generatedartifacts. - Summarize recent runs (by default, the last
n = 3runs) to provide continuity between sessions.
This approach is intentionally lightweight. It does not attempt to “reason” over prior runs automatically; instead, it provides simple recall signals (recent topics and timestamps) and stores the full artifacts so they can be inspected or reused later. For many workflows, that’s enough to make iterative research less repetitive and more trackable.
Designing the agent society: roles, goals, and output contracts
The heart of the system is the set of specialized agents. Each agent is created using a helper function (make_agent) that builds a role-specific system message containing:
- The agent’s role name
- A single goal describing what it must accomplish
- Optional extra rules, usually focused on output formatting
- A final constraint: outputs should be “crisp, structured, and directly usable by the next agent”
Planner
The Planner’s job is to convert a topic into an actionable plan. To keep the workflow machine-readable, it must return JSON with specific keys:
planquestionsacceptance_criteria
This is more than formatting: it creates a contract that the Researcher can depend on. If you want robust orchestration, contracts like this are often more valuable than prompting tricks.
Researcher (with web search tool)
The Researcher answers the Planner’s questions and must return JSON with:
findingssourcesopen_questions
Crucially, the Researcher is augmented with SearchToolkit().search_duckduckgo. The tool is attached directly to the agent, enabling it to call web search during its step. This “web-augmented reasoning” pattern helps ground the output and is intended to reduce unsupported claims.
Writer
The Writer converts the research JSON into a structured research brief and returns Markdown only. Keeping the Writer output clean (no JSON wrapper) makes it easier to publish or pass to downstream systems.
Critic
The Critic is a dedicated quality-control stage. It reviews the draft and returns JSON with:
issuesfixesrewrite_instructions
This “separate critic” pattern is a common way to catch gaps in structure, unsupported statements, unclear reasoning, or missing sections—without asking the Writer to self-evaluate in the same pass.
Finalizer
The Finalizer takes the Critic’s structured feedback and rewrites the brief. Like the Writer, it returns Markdown only. This creates a clean before/after improvement loop: draft → critique → revised final.
Orchestration helpers: enforcing JSON outputs and handling fallbacks
When you operate multiple agents in sequence, formatting errors can break the entire run. To improve resilience, the workflow wraps agent calls in two helper functions:
step_json: runs an agent step, extracts the message text, then tries to parse JSON. If parsing fails, it returns a fallback object like{"raw": txt}.step_text: runs an agent step and returns plain text content as-is.
This pattern centralizes parsing logic and makes the pipeline more tolerant of minor output variability—especially important when you rely on structured contracts across multiple agents.
End-to-end workflow: from topic to finalized brief
The tutorial brings all components together in a single orchestration function: run_workflow(topic: str) -> Dict[str, str]. The sequence is intentionally linear and easy to inspect:
- Show recent memory: prints
mem_last_summaries(3)to provide context on prior runs. - Planning: the Planner generates a structured plan and questions for the given topic.
- Research: the Researcher uses web search and the plan JSON to produce findings and sources.
- Drafting: the Writer turns research into a draft research brief (Markdown).
- Critique: the Critic evaluates the draft and returns structured issues and fixes.
- Final rewrite: the Finalizer applies the critique to produce an improved final brief (Markdown).
- Persistence: all artifacts are stored to
camel_memory.jsonviamem_add_run.
Each run stores a complete artifact bundle, including:
plan_jsonresearch_jsondraft_mdcritique_jsonfinal_md
In the reference example, the workflow is executed with:
TOPIC = "Agentic multi-agent research workflow with quality control"
After running, it prints artifacts["final_md"], which is meant to be immediately usable for reporting, analysis, internal briefs, or downstream automation.
Why this structure improves reliability and scalability
The pipeline demonstrates several practical techniques for making agentic systems more robust:
- Clear role separation: planning, research, writing, critique, and finalization are different cognitive tasks; splitting them reduces prompt overload.
- Machine-readable handoffs: JSON contracts make it easier to validate and programmatically route outputs.
- Evidence grounding: attaching a web search tool to the Researcher encourages sourcing and reduces unsupported outputs.
- Iterative refinement: critique-driven rewriting is a straightforward quality loop that mirrors editorial workflows.
- Persistence for continuity: storing artifacts enables review, reuse, and iterative improvements over time.
Importantly, these choices also improve controllability: if a stage fails, you can re-run only that stage (or swap prompts/roles) rather than regenerating everything.
Conclusion
A CAMEL-based multi-agent pipeline with planning, web-augmented research, critique, and persistent memory offers a pragmatic step beyond single-prompt usage. By enforcing structured contracts and adding a review-and-rewrite loop, you can build agentic workflows that are easier to scale, debug, and trust for research and briefing tasks.
<<>>
Related Articles
- Meta Acquires Manus: Why the Fast-Growing AI Agent Startup Matters for Facebook, Instagram, and WhatsApp
- LLMRouter: A UIUC Open-Source System That Routes Each Query to the Best LLM for Cost, Quality, and Complexity
- MAI-UI: Alibaba Tongyi Lab’s Foundation GUI Agents Push State of the Art in Android Navigation and Grounding
Based on reporting originally published by www.marktechpost.com. See the sources section below.
Sources
- www.marktechpost.com
- https://github.com/camel-ai/camel
- https://github.com/Marktechpost/AI-Tutorial-Codes-Included/blob/main/AI%20Agents%20Codes/camel_multi_agent_research_pipeline_Marktechpost.ipynb
- https://x.com/intent/follow?screen_name=marktechpost
- https://www.reddit.com/r/machinelearningnews/
- https://www.aidevsignals.com/
- https://t.me/machinelearningresearchnews